Monolith to Microservices: My hands-on journey in the last 7 months
Recently, we started an initiative called Event-Driven Architecture with the simple idea- to break a Monolith application into cloud-ready Microservices. In this article, I share my experience till now — the pros and cons of both monolith and micro-services and the unforeseen challenges we faced while breaking the monolith.
Let’s talk about Monolithic applications first.
Monolithic architecture
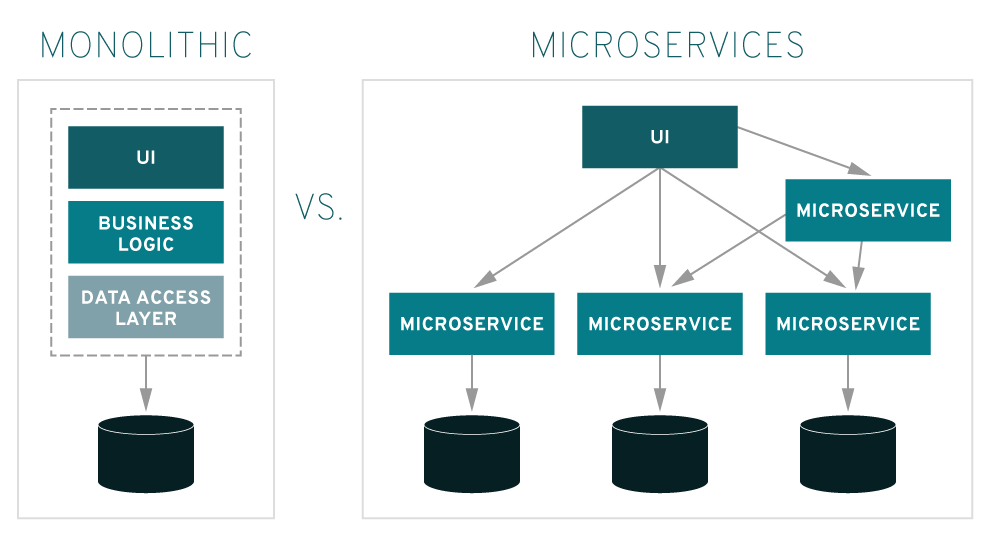
Monolith means composed all in one piece. The Monolithic application describes a single-tiered software application in which different components are combined into a single program from a single platform. Components can be:
- Authorization — responsible for authorizing a user
- Presentation — responsible for handling HTTP requests and responding with either HTML or JSON/XML (for web services APIs).
- Business logic — the application’s business logic.
- Database layer — data access objects responsible for accessing the database.
- Application integration — integration with other services (e.g. via messaging or REST API). Or integration with any other data sources.
- Notification module — responsible for sending email notifications whenever needed.

Pros?
- Simplicity: Monolithic applications are simple to develop, test, deploy, monitor, and manage since everything resides in one repository. There is no complexity of handling different components, making them work in conjunction with each other, monitoring several different components, and whatnot. Things are simple.
Cons?
Let’s see our case first, then we can understand the cons in a much better way.
A Brief History of Scaling FO: Our Case Study
Our original application started as many sites start today, as a single monolithic application doing it all. That single app was called FO. The oversimplified explanation of FO can be a portal where customers can post their logistics-related orders for transportation. It hosted web servlets for all the various pages, handled business logic, and connected to a handful of databases.

As the company grew, so did FO, increasing its role and responsibility, and naturally increasing its complexity. Load balancing helped as multiple instances of FO were spun up. But the added load was taxing FO’s most critical system — its Order profile database.
An easy fix we did was classic vertical scaling — throw more CPUs and memory at it! While that bought some time, we needed to scale further. The Order database handled both read and write traffic and so to scale, replica slave DBs were introduced. As the site began to see more and more traffic, our single monolithic app FO was often going down in production, it was difficult to troubleshoot and recover, and difficult to release new code. Performance was degrading and response time on UI became high with the time. High performance and availability are critical to business. It was clear we needed to “Kill FO” and break it up into many small functional and stateless services.
So here are the challenges which we face:
- Continuous deployment: Continuous deployment is a pain in monolithic applications because even a minor code change in a layer necessitates a re-deployment of the entire application.
- Regression testing: The downside of this is that we need a thorough regression testing of the entire application after the deployment is done because the layers are tightly coupled with each other. A change in one layer impacts the other layers significantly.
- Single points of failure: Monolithic applications like FO have a single point of failure. If any of the layers has a bug, it can take down the entire application.
- Scalability issues: Flexibility and scalability are a challenge in monolith apps because a change in one layer often necessitates a change and testing in all the layers. As the code size increases, things might get a bit tricky to manage.
- Cannot leverage heterogeneous technologies: Building complex applications with a monolithic architecture are tricky because using heterogeneous technologies is difficult in a single codebase due to compatibility issues.
- Not cloud-ready, hold state: Generally, monolithic applications are not cloud-ready because they hold state in the static variables. An application to be cloud-native, work smoothly, and be consistent on the cloud has to be distributed and stateless.
As a result, we started this Event-Driven Architecture initiative by which we can achieve high scalability (means high performance) by breaking down the application into smaller chunks of services, scaling the database nodes, etc.
Let’s talk about EDA in some detail.
What are events?
There are generally two kinds of processes in applications: CPU intensive and IO intensive. In the context of web applications, IO means events. A large number of IO operations mean a lot of events occurring over a period of time, and an event can be anything from a tweet to a click of a button, an HTTP request, an ingested message, a change in the value of a variable, etc.
We know that Web 2.0 real-time applications have a lot of events. For instance, there is a lot of request-response between the client and the server, typically in an online game, messaging app, etc. Events happening too often is called a stream of events.
Event-driven architecture
Non-blocking architecture is also known as reactive or event-driven architecture. Event-driven architectures are pretty popular in modern web application development. Technologies like NodeJS, frameworks in the Java ecosystem like Play, and Akka.io are non-blocking in nature and are built for modern high IO scalable applications.
They are capable of handling a big number of concurrent connections with minimal resource consumption. Modern applications need a fully asynchronous model to scale. These modern web frameworks provide more reliable behavior in a distributed environment.
They are built to run on a cluster, handle large-scale concurrent scenarios, and tackle problems that generally occur in a clustered environment. They enable us to write code without worrying about handling multi-threads, thread lock, out-of-memory issues due to high IO, etc.
Returning to Event-driven reactive architecture. It simply means reacting to the events occurring regularly. The code is written to react to the events as opposed to sequentially moving through the lines of codes.
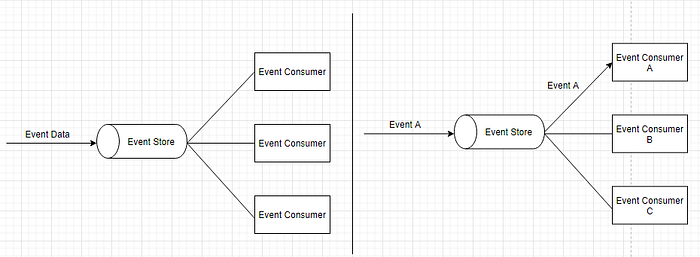
The sequence of events occurring over a period of time is called a stream of events. To react to the events, the system has to continually monitor the stream. Event-driven architecture is all about processing asynchronous data streams. The application becomes inherently asynchronous.
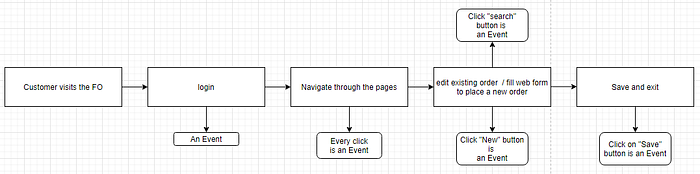
How EDA applied to our FO?
User perspective:

EDA perspective:
Cool, but where is Micro-services in this?
In a microservices architecture, different features/tasks are split into separate respective modules/codebases that work in conjunction to form a large service as a whole. This particular architecture facilitates easier and cleaner app maintenance, feature development, testing, and deployment compared to a monolithic architecture.
Following EDA, we can create multiple event producers and event consumer component-each as a microservice.
These micro-services strictly follow a service line boundary and are loosely coupled. For example, an Event producer will never know where the consumer is or what will happen after it posts data to the event store.
Similarly, a consumer never knows who posted the data in the event store and how many other consumers are running parallelly.
Some of the pros which we saw are:
- No Single Points of failure: Since microservices are a loosely coupled architecture, there is no single point of failure. Therefore, even if a few of the services go down, the application as a whole is still up.
- Leverage heterogeneous technologies: Every component interacts with each other via a REST API Gateway interface. The components can leverage the polyglot persistence architecture and other heterogeneous technologies together like Java, C#, Ruby, NodeJS, etc.
Polyglot persistence uses multiple database types, like SQL and NoSQL together in architecture. - Independent and continuous deployments: The deployments can be independent and continuous. We can have dedicated teams for every microservice, and it can be scaled independently without impacting other services.
Let’s not skip the cons:
- Complexities in management:
Microservices is a distributed environment where there are so many nodes running together. As a result, managing and monitoring them gets complex.
We need to set up additional components to manage microservices such as a node manager like Apache Zookeeper, Grafana, Kibana, which are a distributed tracing service for monitoring the nodes, etc.
We need more skilled resources and maybe a dedicated team to manage these services.
- No strong consistency:
Strong consistency is hard to guarantee in a distributed environment. Things are eventually consistent across the nodes, and this limitation is due to the distributed design.
Conclusion
What to decouple and when?
Migrating a monolithic system to an ecosystem of microservices is an epic journey. The ones who embark on this journey have aspirations such as increasing the scale of operation, accelerating the pace of change, and escaping the high cost of change. They want to grow their number of teams while enabling them to deliver value in parallel and independently of each other. They want to rapidly experiment with their business’s core capabilities and deliver value faster. They also want to escape the high cost associated with making changes to their existing monolithic systems.
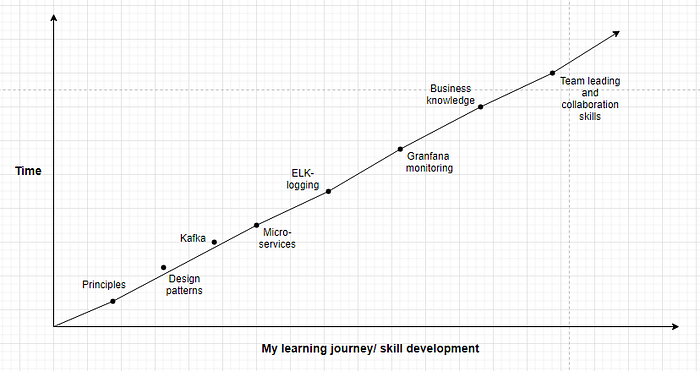
My learning curve
Below is a summarized graph of my personal learnings:
Lastly, an excellent article about Event sourcing can be found here.
